はじめに
何年か前から趣味でインフラ管理をしているのですが、最近自分のインフラ環境を誰かに共有する機会が増えてきました。その時に口頭でインフラを説明しようとすると大変なので、こうしてブログに文章として残してみようと思います。
構築方法は記述していませんが、使うソフトウェア等を選ぶ目的で誰かの役に立てば幸いです。
概要
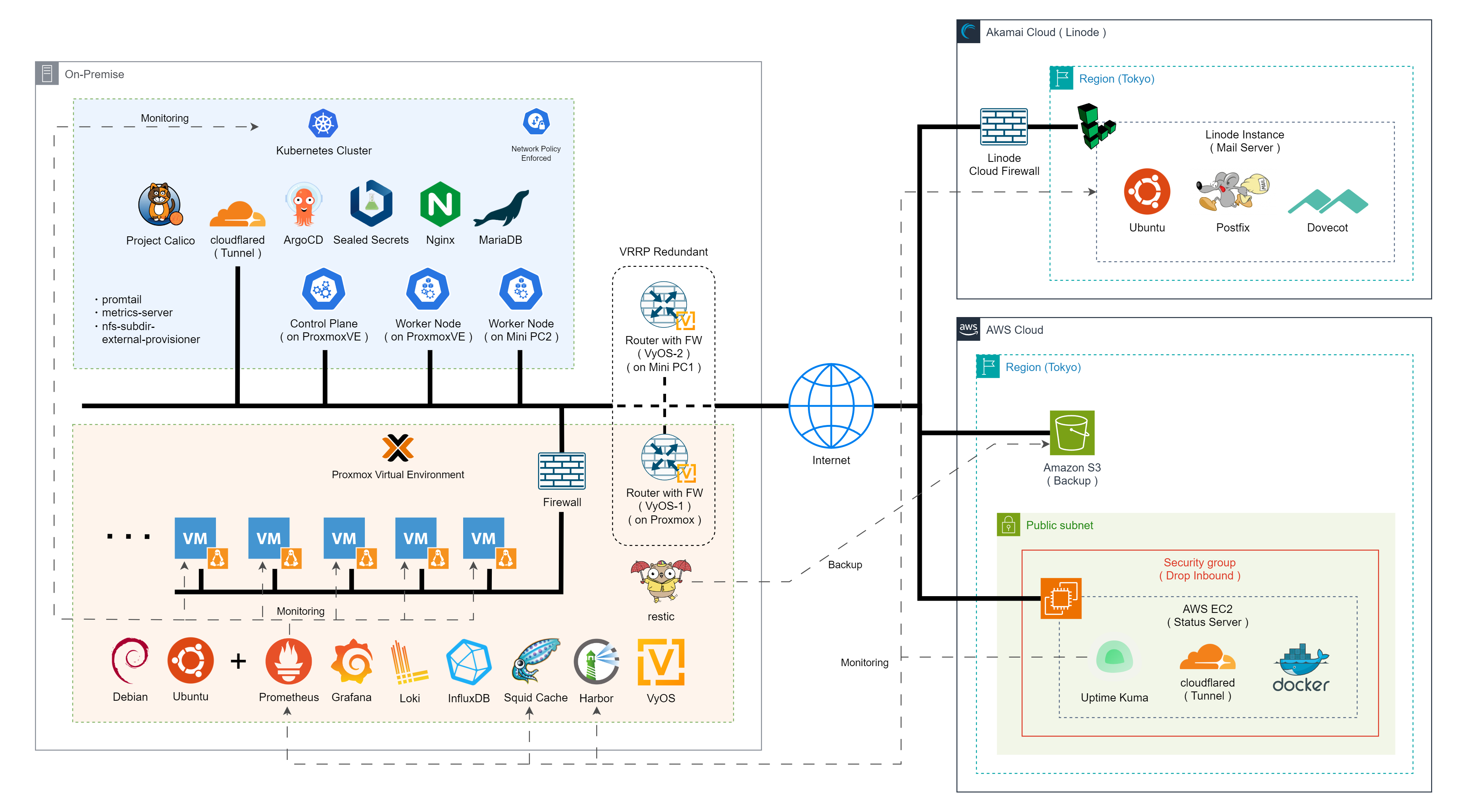
2024年6月時点で管理しているインフラは図に示す通りです。左の枠が自宅サーバー、右は上から Linode、AWS です。それぞれについて順番に説明していきたいと思います。
自宅サーバー (Proxmox)
現在、自宅サーバーには3つのデバイスがあり、それぞれ Proxmox, VyOS, Debian がインストールされています。写真を貼ろうと思いましたが、埃っぽいので勘弁してください。イメージとしては Proxmox は普通のデスクトップPC、残り2つはミニPCを思い浮かべて貰えると良いです。
基本的に全ての主要サービスは Proxmox 上で動いています。例えば Kubernetes クラスタのコントロールプレーンであったり、後述する VRRP が設定されている VyOS のマスターノードもこの Proxmox 上の VM として起動されています。
起動しているサービスは Minecraft サーバーや、なんでも用途の Ubuntu など色々ありますが、画像には主にインフラに関係したサービスのみを掲載しています。ここでもインフラ関係の物のみに留めて説明しようと思います。
Prometheus, Grafana, Loki, InfluxDB
この4つは全体のメトリクス管理を行っています。それぞれ以下のような役割を果たしています。
| サービス | 役割 |
|---|---|
| Prometheus | 各 VM の Node Exporter からメトリクス収集し保存する。また、異常を検知してアラートを発する |
| InfluxDB | Proxmox から出力されるメトリクスを収集し保存する |
| Loki | Kubernetes の Pod から出力されるログを収集し保存する |
| Grafana | 上記3つのサービスを用いてデータを可視化する |
Grafana のダッシュボードは有志が公開しているダッシュボードを使ったり、自作したりして見やすくしています。
Proxmox:
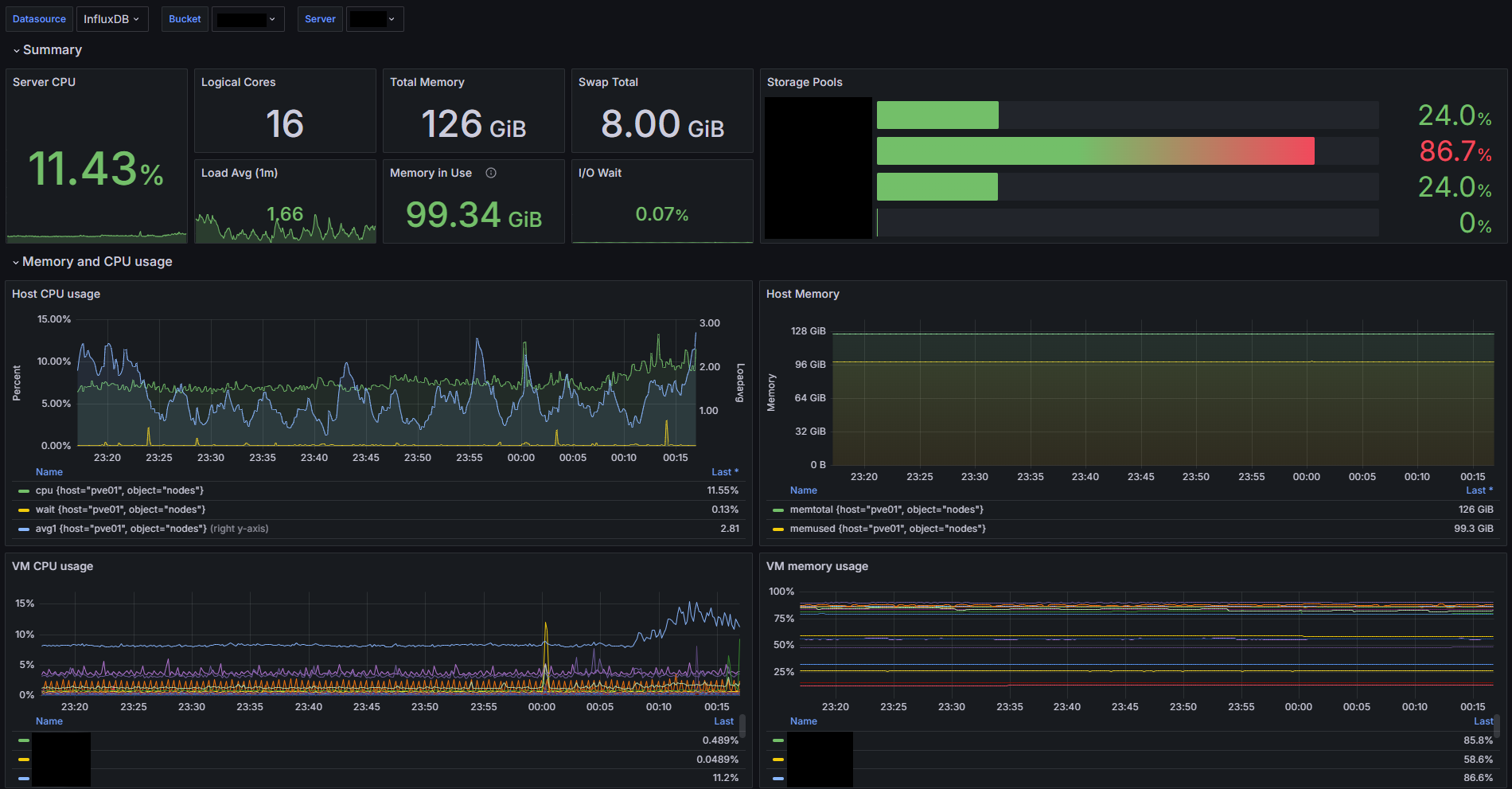
Kubernetes:

また Alertmanager を用いて、Prometheus に記録された Node Exporter のメトリクスを元に異常検知を設定しています。アラートが Firing 状態になると、Discord に通知が飛んでくるようになっています。
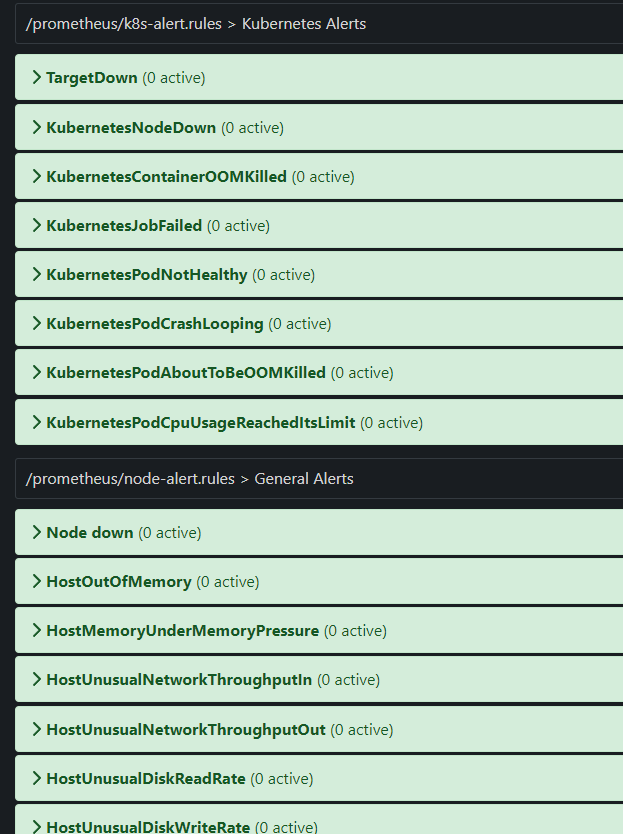
アラートの設定は この辺り の有志が作成したものを参考、また利用させて頂きました。
Squid Cache
Squid Cache はキャッシュプロキシで、今回は apt リポジトリに対するキャッシュを適用するために使用しています。詳しくは別の記事 (apt用のキャッシュプロキシをSquidで構築する) に書いているので、興味があればそちらを確認してください。
Harbor
Harbor は Kubernetes 用のプライベートレジストリです。
Docker Hub とかにイメージをアップロードしたくはないが、クラスタ内で独自のイメージを利用したい時に使用します。
Kubernetes 内に生やしても良かったのですが、まだ安定してクラスタを運用できる自信がないため、コンテナレジストリは別で構築しておいた方がトラブルシューティングが楽だと考えて VM として起動しています。
restic
restic は増分バックアップツールです。
データが失われると困る主要サービスのバックアップを定期実行しています。バックアップは AWS の S3 に保存されるように設定されています。
自宅サーバー (Kubernetes)
kubeadm で構築した純正 Kubernetes クラスタを運用しています。コントロールプレーンは Proxmox 上の VM として起動しており、ワーカーノードの片方を同じくVM、もう片方はミニPCに Debian をインストールして起動しています。
雑多なアプリケーションを起動しており、例えば cloudflared とか、このブログも Kubernetes クラスタ上で起動されています。
マニフェストは ArgoCD を用いて GitHub のプライベートリポジトリで管理しています。また、Renovate を用いてイメージのタグ更新通知を受け取っています。
Renovate によってプルリクが生成されるので、Approve してマージするだけでインフラが更新できます。
こだわっている点として、Network Policy を適切に設定しているところがあります。
例えばこのブログを例に取ると、nginx のみが外部と通信でき、ブログ本体は nginx と MariaDB のみ、MariaDB はブログ本体のみとしか通信できないように制限されています。
$ kubectl get netpol --all-namespaces | wc -l
32自宅サーバー (VyOSルーター)
ルーターには VyOS を利用しています。
Proxmox上の VyOS と物理デバイス上の VyOS の2台があり、VRRP を用いて冗長化を行っています。
マスターは Proxmox 上の VyOS に設定されています。物理デバイス上の VyOS はバックアップです。
なお物理デバイスの方は発熱が目立つので、夏は基本的に起動していません。
冬は積極的に起動して暖房用途として使用しています。
Linode
Linode では Postfix を用いたメールサーバーを稼働させています。
自宅サーバーで起動しても良いのですが、OP25B や安定性の観点からクラウドでの起動を選びました。
[email protected] 宛てのメールはこのメールサーバーに届きます。
Postfix は老舗のソフトウェアなのでバグの少なさに安心感があるのですが、モダンな環境に塗り替えるのを考えると stalwartlabs/mail-server とかに置き換えるのも有りかなと思ったりします。
AWS
S3
先述した restic のバックアップはこの S3 に保存されます。
ディスク破損に備えたバックアップです。現状バックアップが適用できていないサービスが一部あるので、今後全ての主要なサービスに適用したいと思っています。
ステータスサーバー
AWS では UptimeKuma を用いて ステータスサーバー を起動しています。
利用者が多いサービスを運用しているわけではないので、ステータスサーバーを必要とする人は居ません。
どちらかというと自分用のモニタリングの意味が強く、監視しているサービスが落ちた場合に Discord 経由で通知が来るようになっています。
特に VM を監視している Prometheus 自体が落ちていると異常が起こっても通知が来ないので、その Prometheus 自体をステータスサーバーで監視するように設定されています。
総括
現状クラウドを利用しているのは一部のみであり、料金面の関係でクラウドは出来る限り利用しない方針となっています。
この規模の自宅サーバーは維持費が安いですが、自宅が停電したりネットワークが切れたりすると、大半のサービスが止まってしまうという欠点があります。
財布と技術力に余裕が出来たら、「自宅サーバーが落ちた時にクラウドで自動起動する」みたいな設定ができると、もっと安定する上に面白いインフラ構成に出来るかもしれません。
今後はインフラ構成をある程度変更したら、ブログで共有していこうと思います。